
EasyVista, diversos scripts
Ahora todos los scripts que tenía para Redmine, por cambio de herramienta, los tengo que adaptar a EasyVista.
Pereza total. Solo adaptaré los más necesarios y según los vaya necesitando. Tiempo.
Básicamente sigue siendo lo mismo. Bajarse los datos con curl y esta vez utilizar jq para estructurar los json y resto que haga falta con awk.
Sigo intentando no poner código completo.

Termina 2024 con varios scripts en bash
Utilizando sobre todo awk y curl
- fedicom3.sh: envía pedidos, descarga albaranes con esta versión de protocolo
- resumen_gasluz.sh, grafica (gnuplot) y saca varios ratios sobre consumos de estos tipos
- entrenos.sh, mejorado, muchos más gráficos, ratios de kms, sesiones, horas, por meses, por circuitos, por bici utilizada, zapatillas, fc, ...
- tickets.sh descarga de redmine y easyvista para diversas estadísticas
- tid2json2txt.sh, varias tiddlywikis que tengo, sap y gestión de temas en curso, se exportan a otros formatos donde pueda consultar de otras formas via web
- busca_me.sh, motor principal de búsquedas de ficheros
- hazcopia.sh, copias de seguridad con git y rclone
- calcrontab.sh y calen.sh , genera fichero texto y pdf diario del planning a seis semanas vista
- viajes.sh, genera ficheros varios para web consulta mis viajes
- libros.sh, lo mismo pero para libros
y más ...
Mapa marcando los lugares que hice carreras de orientación
Aprovechando que todavía Google Maps ofrece el crear mapas propios y teniendo los registros de cada actividad deportiva que hago, se me ocurrió crear un mapa que indique los lugares en los que he hecho carreras de orientación, marcando en ellos el lugar exacto de la salida, así como detalles de la carrera.
Cuando luego se viaja por otros motivos, gusta saber por dónde hice una carrera y si existe un mapa cercano que lo disfruté.
Así que, teniendo los tracks de las carreras, tengo medio automatizado el poder añadir estos puntos, para que quede parecido a lo que se ve en la imagen.
Al pinchar en cualquier icono se ven datos de la carrera en cuestión que pueden ayudarme a recordar mejor cómo fue ese evento.
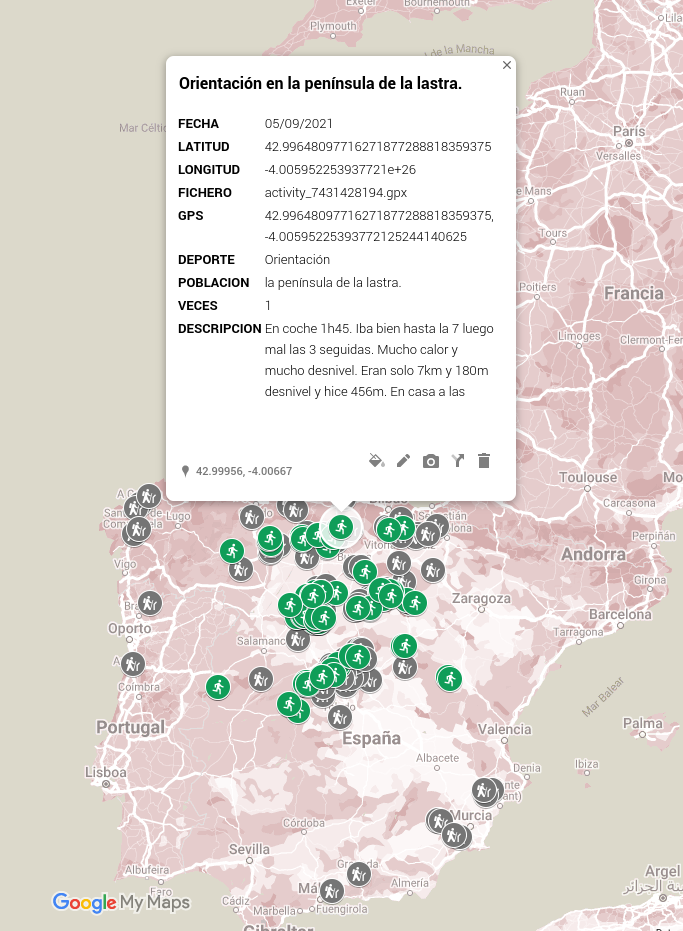
pd: el sacar los datos de los tracks, está hecho con bash y lua y se hizo en 2021.
No pongo código. No hay que subir ningún tipo de código ya.
Fedicom historia programas realizados
Los años son aproximados pues pasó ya tiempo y el paso de datos de un ordenador a otro ha dificultado el saber con exactitud la fecha primer uso.
Última actualización oct-2023: web para paso pedido fedicom versión 3
2004 ZacoFedicom
Realizado en Delphi, se ofreció gratuitamente a las farmacias que todavía no disponían de software propio de gestión.
Al principio solo disponía de una pantalla en la que buscar artículos de forma rápida, elegirlos añadiendo cantidad para confeccionar un pedido y emitirlo via Fedicom bien a Valladolid o al almacén de Zamora.
Se podía elegir tipo de pedido, normal, especial, aplazado. Con un botón se actualizaba la base de datos via ftp.
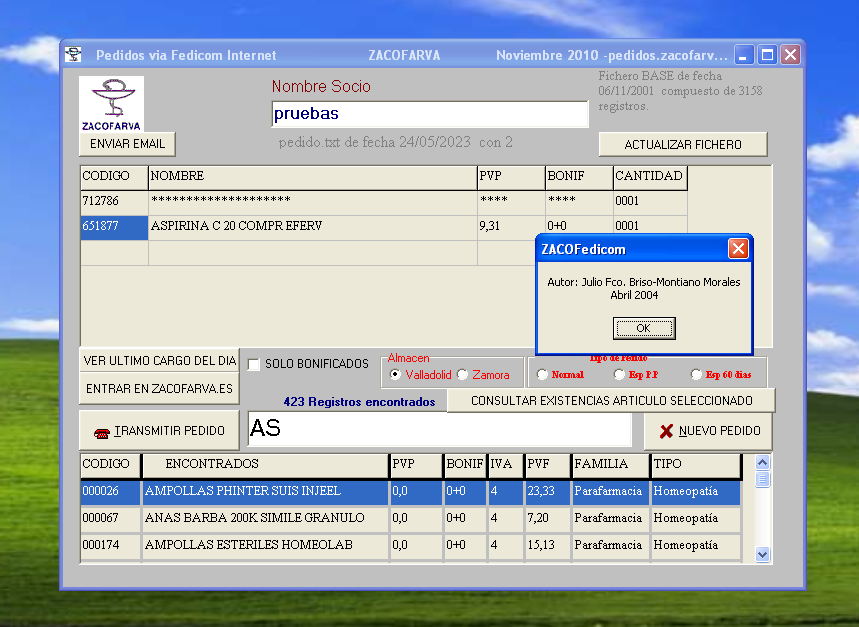
El total de funciones que tuvo:
- actualizar bbdd mediante ftp visualizando en todo momento fecha de los datos
- buscar artículos de forma rápida indicando su bonificación, precios y datos
- emitir a 2 almacenes
- pedido especial o normal
- visualizar albarán descargándose el html del último albarán cargado en cooperativa
- entrar directamente en la página web
- consultar existencias sin tener que emitir el pedido
- lanzar el programa cliente de email
- configurable ip y puerto de pedidos
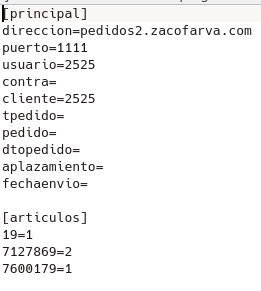
2012 fedicom.py
Hecho en python podía transmitir pedidos a partir de un fichero de texto .ini.
Consta de una parte donde se cogen los parámetros de transmisión y otra con los artículos, cantidades, descuentos.
2012 curroflask.py
Casi a la vez hice una página web que utiliza python. Hecha con Flask ha sido instalada en varios servidores, desde locales en casa, VPS.
Aún se mantiene y todavía veo que lo utilizan varias farmacias para transmitir pedidos. Tiene esta pinta en https://fedicom.julb.es
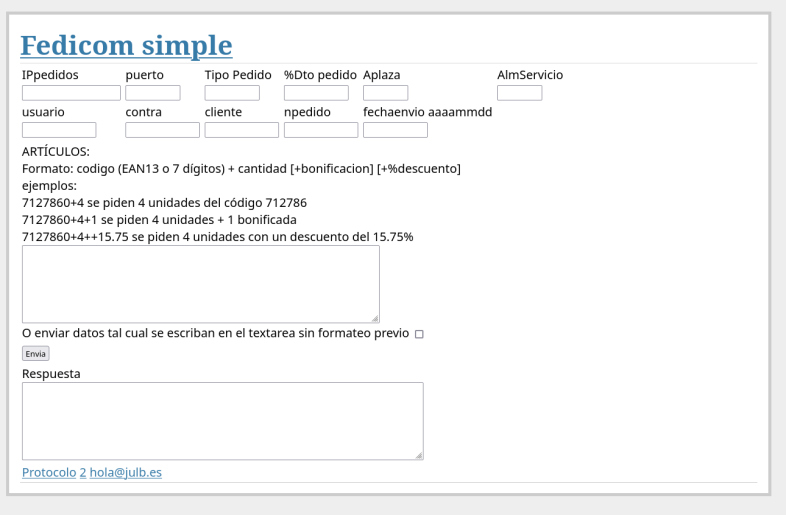
- ip, puerto, tipo pedido, %dto, aplazamiento, almacén servicio, numpedido, hastafecha
- se pueden meter eans o cns, dto individual por cada línea
- se utilizaba también para crear transfers
- se muestra el resultado tal cual se recibe
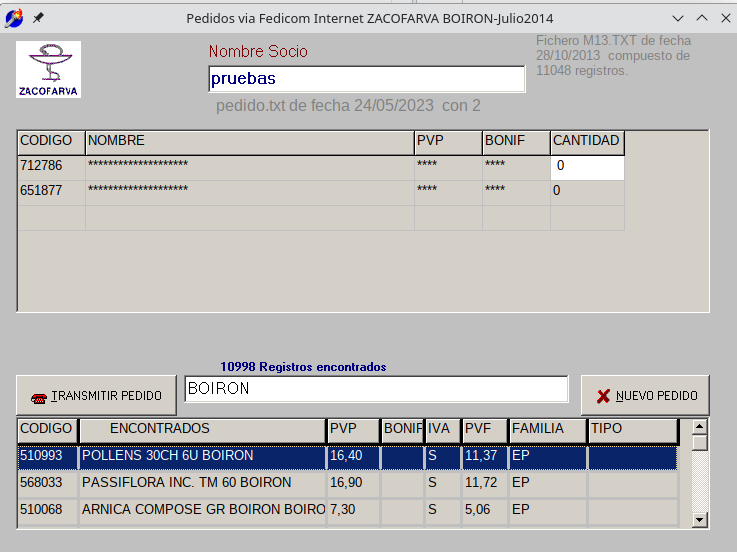
2013 ZacoFedicomBoiron
Lo mismo que ZacoFedicom pero esta vez era utilizado por el personal para hacer pedidos a Boiron via fedicom.
Se descargaba la base de datos propia de Boiron y solo transmite a este laboratorio.
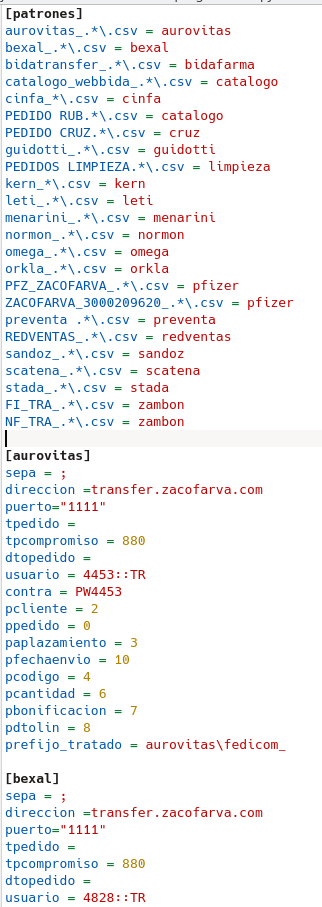
2015 csvtofedicom.pyw
Programa hecho en python. Ahorró mucho trabajo pues asociado a un programa automático de descarga de transfers (incluso por email, descargaba los adjuntos) emitía a la propia cooperativa los transfer por fedicom.
Los laboratorios podían hacer llegar esos transfer en formato excel (se convertían a csv), tsv, por ftp o por email o se bajaban también por servicios web.
Se trataban los adjuntos cada uno con su patrón indicado en un fichero .ini, donde se le decía qué separador se utilizaba, en qué campo estaba el artículo, el cliente, la cantidad, el descuento, etc ...
Admitía bitransfer/stockonline/compromisos de compra
Este es un vistazo del fichero .ini con el que el programa lanzaba los pedidos.
2016 fedicomserver.go
Quise aprender Go y me puse otra vez como objetivo emisión pedidos fedicom. Pero una vez resuelto el objetivo, decidí hacer también un servidor de fedicom.
Un programa, que en caso de fallar el concentrador de pedidos, sirviera para recibir pedidos fedicom.
Estuvo instalado por si acaso cascaba el concentrador de pedidos principal en varias máquinas.
Le fui añadiendo opciones, también configurables con un fichero .ini, como:
- puerto de escucha
- si se reenvía el pedido a otro servidor fedicom o no
- es decir, podía hacer de puente. Recibir el pedido y una vez tratado, emitirlo a otro servidor fedicom
- consultaba al ERP sobre el cliente, datos de acceso.
- informaba de las faltas reales. Es decir, hacía consulta al ERP con las existencias y podía responder si el artículo solicitado se podía servir o estaba en falta.
- creaba un fichero csv del pedido, por si se necesitaba sacar para grabar de otra forma en el ERP
- luego, para desconectarlo del servidor y con fines didácticos, podía simular las faltas con distintos porcentajes de falta, para recibir respuestas aleatorias.
- podía reenviar el pedido obviando las faltas.

2013 y 2018 fedicom.sh
En bash con herramientas gnu, utizando netcat o telnet se pueden transmitir pedidos por fedicom.
El problema sería calcular de antemano los controlos finales del fichero a transmitir (unidades y líneas) y tener cuidado con las posiciones dentro del fichero.
En realidad cualquier programa que establezca comunicación con puertos socket (hice con Lua, python y Go).
con linux y telnet: cat pedido.txt | telnet pedidos.zacofarva.com 1111
o con windows y netcat: type pedido.txt | ncat -v -w 8 ip puerto
o con linux y netcat: cat ${1} | nc -v -w 8 $ip $port
2023 fedicom3.sh
En bash, emite pedidos con servicios web con curl. Con un fichero .ini de configuración y otro de las líneas a pasar confecciona el pedido y lo emite.
Pensaba que ya no lo iba a hacer.
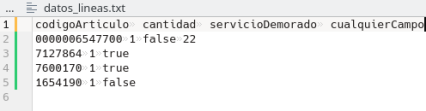
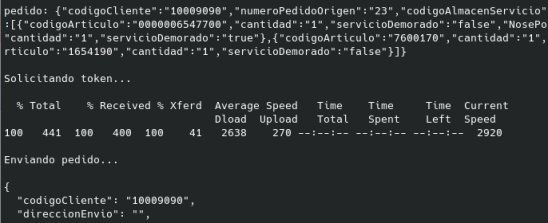
2023 Web fedicom versión 3 y programa python
fedicom3.py pasa o un fichero ya formateado json para ello o a partir de un fichero csv.
Aprovechando el tenerlo creo web con las mismas bases:
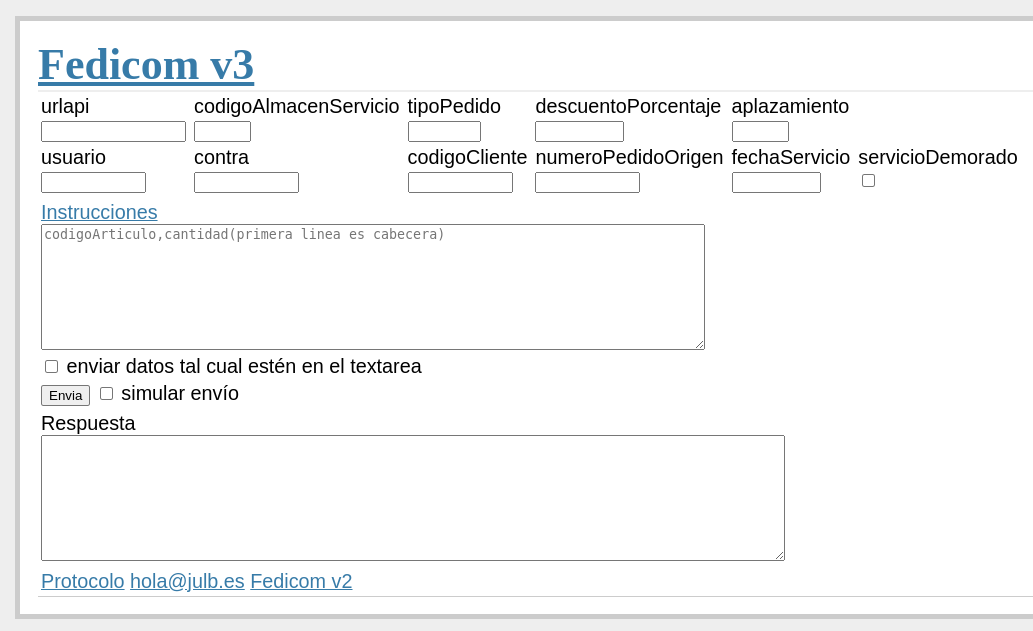
Espero no saquen versión 4 de fedicom, por favor ...
otras herramientas menores fedicom
- como excel que pegando un fichero plano de un pedido fedicom2 en una hoja desgrana todos los campos fedicom, sacando usuario, contraseña, artículos, etc
Buscar de forma rápida las palabras que quieras dentro de tus documentos
Tengo unos cuantos miles de ficheros de texto del tipo .txt .adoc .md .sh
Muchas veces me surge la duda de cómo resolví tal problema o dónde anoté aquella incidencia.
He pasado ya por muchas formas de tener almacenada la información, muchos tipos de wikis. Obsidian es ahora la que está de moda y parece la más avanzada hoy.
Pero sin duda para mi la mejor sigue siendo https://tiddlywiki.com/. Tener todo en un fichero local html sin necesidad de servidor es una ventaja. Y su búsqueda es muy buena.
Pero tiene otros inconvenientes. Total que decidí volver a tener toda la documentación en ficheros de texto, sean en formato markdown o asciidoc. Los ficheros de texto son atemporales "informáticamente" hablando, ligeros, cómodos de editar, reutilizables.
¿y cómo buscar dentro de todos esos ficheros?
Con bash y herramientas gnu. Este script lo podemos lanzar de forma
busca <palabra1> <palabra2> ... <palabra.n>
El motor es grep
```
grep --include=\*.{md,adoc,txt,sh} --exclude="encontrado.md" --exclude-dir={"DOIT","blog"} -Ril $1 ~/Documentos/ > zbusca
```
para luego hay que hacer búsquedas recursivas de cada palabra.
```
for i in $palabras
do
cat $ant | xargs grep -li $i 2>/dev/null > zbusca$i
ant=zbusca$i
done
```
y nos devolverá un fichero html con todos los ficheros que contienen todas las palabras buscadas (AND no OR), y los registros son linkables de forma que al pinchar sobre ellos nos mostrará el contenido. Ese fichero de resultados lo genero en markdown y luego convierto con pandoc a html.
En el script se define y ofrece:
- qué tipo de extensiones tienen los ficheros a rebuscar
- desde qué carpeta empezamos a buscar
- se pueden excluir carpetas o ficheros para que no mire dentro de ellos
- devuelve fichero con los resultados en markdown y html
- contabiliza el total de ficheros que contienen las palabras buscadas.
Este script funciona en local en el equipo y con el navegador o sin él se pueden ver los resultados.
Pero también necesito hacer esta búsqueda desde fuera de casa, desde el móvil o cualquier ordenador, sin necesidad de VPN pero de forma privada.
Eso me costó más, porque hay muchas soluciones todas ellas con sus ventajas y grandes inconvenientes. Ya veremos si lo cuento.
```
#!/usr/bin/env bash
# Función: busca en todos mis documentos de tipo texto, .md .adoc .txt .sh los argumentos que se le pasen
# Fecha creación: 13.05.2023
# Autor: Julio Briso-Montiano
# Versión: 1.0
# Detalle:
# - meter en .bash_aliases la ruta de este script
# - crea encontrado.md y html en la carpeta de este script con los resultados linkables
# - se ve mejor en chrome que en kate para poder hacer click en los md
#
#set -euo pipefail
filout="/home/julio/Documentos/06-Zaprogramas/bash/buscabash/encontrado.md"
filhtml="/home/julio/Documentos/06-Zaprogramas/bash/buscabash/encontrado.html"
if [ $# -lt 1 ]
then
echo "Formato: ./busca.sh <algo1> <algo2> ...>"
fi
palabras="$@"
#find ~/Documentos -type f \( -name "*.txt" -o -name "*.sh" -o -name "*.md" -o -name "*.adoc" \) -exec grep -l ${1} {} + > zenficheros
# mejor
grep --include=\*.{md,adoc,txt,sh} --exclude="encontrado.md" --exclude-dir={"DOIT","blog"} -Ril $1 ~/Documentos/ > zbusca
ant=zbusca
for i in $palabras
do
cat $ant | xargs grep -li $i 2>/dev/null > zbusca$i
ant=zbusca$i
done
echo -e "Búsqueda de \"""$@""\" encontrados en estos ficheros:\n---\n---\n" > $filout
while IFS= read -r line
do
echo -e "[""$line""](""$line"")" >> $filout
echo -e "\n" >> $filout
done < $ant
echo -e "\n---\n" >> $filout
numero=$(cat $ant | wc -l)
echo -e $numero" encontrados\n" >> $filout
echo $(date) >> $filout
rm zbusca*
pandoc -f markdown -t html5 -o $filhtml $filout
more $filout
```
Excel varias pestañas y datos dispersos en varias filas o columnas pasarlo a fichero tabulado
Me pasan fichero excel con multitud de pestañas tal que así

Dentro de cada hoja hay datos agrupados por Repartos como código cliente, nombre, población y orden
pero pueden estar en cualquier parte de la hoja excel (columna y fila), en este caso empiezan en la columna A y F

pero también pueden empezar en la columna B fila 23

Se require fichero tabulado en el cual la primera columna sea el nombre de la pestaña/hoja del excel
y el resto las columnas antes mencionadas: reparto1 o reparto2, codigocliente, población, orden
este sería un ejemplo para pestaña 174 reparto 2

En lugar de manipular todos estos datos a mano, un script utilizando herramientas disponibles en linux genera
el fichero deseado en 1 segundo:
```
#!/usr/bin/env bash
# Función: crear YVLG_KMS_ORDEN segun excel que nos pasen
# Fecha creación: 13.04.2023
# Autor: Julio Briso-Montiano
# Versión: 1.0
# Detalle:
# - correr primero xlsx2csv -s 0 -d tab EXCEL_ORDEN.xlsx > EXCEL_ORDEN.txt
# - tu responsabilidad chequear
# - si quieres excluir alguna ruta renombra la hoja del excel que sea añadiendo alguna letra p.e "x"
#
set -ueo pipefail
if [ $# -lt 1 ]
then
echo "Formato: ./kms.sh <excel.xlsx>"
exit
fi
xlsx2csv -s 0 -d tab $1 > tmpkms.tsv
awk -F"\t" '{
gsub("\r","")
if ( substr($1,1,7) == "-------" && NF == 1) {
gsub(" ","")
split($1, a, "-")
#ruta=sprintf("%06i",a[10])
ruta=substr("000000"a[10],1 + length("000000"a[10]) - 6)
}
if ( ruta*1 > 1 )
for (i=1; i <= NF; i++) {
if ( match($i," Reparto ") ) {
reparto=substr($i, RSTART+9,1)
colreparto[i]=reparto
}
if ( ($i*1 > 10000000 && $i*1 < 19999999) || $i == "CE20" ) {
if ( $i == "CE20" )
tipo="A"
else
tipo="E"
print ruta,colreparto[i],"01.01.2023","31.12.9999",$i,$(i+3),tipo,"X"
}
}
}' OFS="\t" tmpkms.tsv > tmpyvlg_kms_orden.tsv
sort -t$'\t' -k1 -k2 -nk6 tmpyvlg_kms_orden.tsv > yvlg_kms_orden.tsv
echo -e "Generado fichero yvlg_kms_orden.tsv"
```
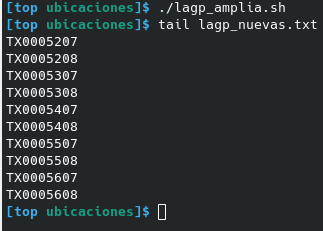
Ampliación de registros dependiendo de que otros que ya existan de antemano
En el almacén quieren optimizar el espacio en las baldas de las estanterías y van a ampliar a 2 ubicaciones más.
A nosotros nos dicen que aquellas baldas que tenga hasta 6 posiciones dentro de ellas, que creemos la posición 7 y 8.
Nos pasan el fichero total de todas sus ubicaciones ya creadas pero no aportan ninguna regla sobre ellas.
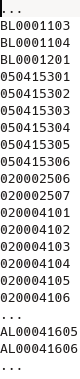
Al ver el fichero que nos dan vemos que:
- los registros tienen distinta longitud
- algunos registros ya terminan en 7, no tenemos que sugerir su creación
- no todas "las series o patrones" que pudiera deducirse que siguen los registros de ubicaciones tienen hasta posición 6
Nos piden que solo lo que termine en 6 tenemos que crear el registro 7 y 8, a no ser que exista ya.
AWK una vez más con pocas líneas nos las creará:
el fichero que nos dan lo llamaremos lagp.txt lo leemos previamente para saber las que ya existen solo si termina en 6 miramos de crear la 7 y 8
```
dos2unix -q lagp.txt
awk '
FNR==NR { lagp[$1]="e"; next}
END {
for ( ubi in lagp ) {
lon=length(ubi)
if ( substr(ubi,lon-1,2) == "06" )
for ( bandeja=7; bandeja<=8; bandeja++ ) {
nue=substr(ubi,1,lon-1)bandeja
if ( lagp[nue] != "e" ) print nue
}
}
}' lagp.txt | sort > lagp_nuevas.txt
```
En 1 segundo tenemos todos las ubicaciones nuevas sea cual sea el patrón que tenga cada parte del almacén.
Google Books descargar las portadas de nuestra biblioteca
Mantengo una hoja de cálculo con varios datos sobre los últimos libros que he ido adquiriendo.
En ella están datos, como ISBN, título, autor, editorial, precio, mi valoración, fecha en la que lo leí, y si lo empecé pero no me enganchó, así que se quedó en "empezado"
De momento en fichero local pero la verdad que de lo mejor que he visto en Google Books. Pasé por GoodReads pero tampoco me fio.
https://www.julb.es/exportar-datos-de-google-books-e-importar-a-goodreads.html
Cualquier día cierran o cambian condiciones de servicio y te quedas colgado, así que de momento, datos en local.
De ese fichero me gustaría poder ver la portada de los libros, la verdad es que una imágen es más fácil de recordar que un título.
Paso de hacer fotos de cada libro así que miré la forma de descargar la portada utilizando la api de Google.
Y sí, si tienes el ISBN es así de fácil, en 1 línea.
curl https://www.googleapis.com/books/v1/volumes?q=isbn:8483465205 | grep "selfLink" | cut -d "\"" -f 4 | cut -d "/" -f 7 | xargs -I @ wget "https://books.google.com/books/publisher/content?id="@"&printsec=frontcover&img=1&zoom=1" -O @.png
Pero claro. Ya que tengo datos, me gustaría comprobar con los que tiene Google así que me lie bastante. Que si nombrar la imagen de la portada con el título, año de publicación ...
Se trata de pasarle a mi script un fichero con todos los ISBN que tengo y obtener todos los valores que necesito.
La API de Google devuelve un json, probé a obtener los valores que me interesaban con jq pero la verdad es que se notaba el incremento de uso de cpu y de tiempo. En cambio con utilidades gnu como grep, sed y cut conseguía lo que quería de forma más rápida y barata.
```
while IFS=$'\t' read -r isbn tit n
do
titulo=$(echo $tit | sed 's/[:;-\/.,?¿!¡\"\(\)]//g' | tr " " "_" )
gid="" && gtitulo="" && gautor="" && geditorial="" && gpublicado="" && gportada=""
if [[ ! -z $isbn ]]
then
gid=$(curl --no-progress-meter https://www.googleapis.com/books/v1/volumes?q=isbn:$isbn | grep "selfLink" | cut -d "\"" -f 4 | cut -d "/" -f 7 | cut -d$'\n' -f 1)
if [[ ! -z $gid ]]
then
glibro=$(curl --no-progress-meter https://www.googleapis.com/books/v1/volumes/$gid)
existethumbnail=$(echo $glibro | grep -q "thumbnail" && echo "si" || echo "no")
gautor=$(echo $glibro | grep -Po '"authors":.*?[^\\]",' | cut -d "\"" -f 4)
gtitulo=$(echo $glibro | grep -Po '"title":.*?[^\\]",' | cut -d "\"" -f 4)
geditorial=$(echo $glibro | grep -Po '"publisher":.*?[^\\]",' | cut -d "\"" -f 4)
gpublicado=$(echo $glibro | grep -Po '"publishedDate":.*?[^\\]",' | cut -d "\"" -f 4)
if [[ $existethumbnail == "si" ]]
then
titulo=$(echo $gtitulo | sed 's/[:;-\/.,?¿!¡\"\(\)]//g' | tr " " "_" )
wget -O portadas/$titulo.png --no-verbose "https://books.google.com/books/publisher/content?id="$gid"&printsec=frontcover&img=1&zoom=1"
gportada="https://books.google.com/books/publisher/content?id="$gid"&printsec=frontcover&img=1&zoom=1"
fi
fi
fi
echo -e $isbn"\t"$gid"\t"$gtitulo"\t"$gautor"\t"$geditorial"\t"$gpublicado"\t"$gportada | tee -a titulo_isbn_idgoogle.tsv
done < isbn_falta.csv
```
Tags: bash
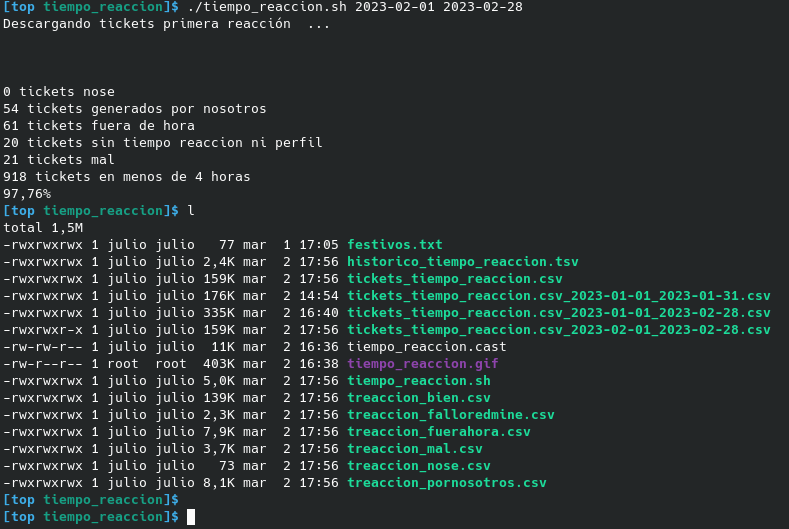
Redmine, diversos scripts III
Otro script en bash y sobre todo awk.
Es lo que mas me viene siempre a mano en cuanto se me ocurre automatizar alguna tarea, o sobre todo sacar resumen de una fuente ingente de datos.
Esta vez el script tiempo_reaccion.sh exporta tickets de redmine entre las fechas que se le meta como parámetros y analiza el tiempo de respuesta en conjuntoe:
- descarga todos aquellos tickets entre fechas
- los que tengan tiempo de respuesta superior a una dada analiza que:
- si fueron dados de alta durante el finde de semana los excluye (desde el viernes por la tarde)
- si fueron dados de alta fuera jornada laboral en día de diario también los excluye
- si son tickets creados por nosotros, no contabilizan para el tiempo de respuesta
- crea por cada casuística 1 fichero csv
Como siempre mola obtener todos esos datos de forma rápida y se agradece no tener que trabajar de forma manual con el excel.
awk es una herramienta bestial, creada hace muchos años y que se maneja muy bien con cantidad de datos enorme.
Redmine, diversos scripts II
Otro script en bash amanuel.sh (así, tal cual, pasando de todo) que hace lo siguiente:
- descarga todos aquellos tickets con determinadas características
- los muestra por pantalla y pregunta si se sigue con el proceso. Si es así:
- los cambia de categoría a Control de Cambios
- los cambia de tipo a Petición
- los asigna al compañero estipulado
Quita bastante trabajo evitando entrar de 1 en 1 en cada ticket para hacer estos cambios.
Redmine, diversos scripts
Fin de semana dedicado a crear diversos scripts que manejen la información de Redmine.
Varios para descargar los tickets hechos por mi y que me haga simples recuentos; otros con varias condiciones de proyectos, asignados, etc ..
Los que más me han gustado son 2:
quita_firma.sh que elimina todas las firmas legales que se van añadiendo en el ticket según la gente va contestando los emails. No se cómo aguantamos tanto la incomodidad de la jerga legal que se mete en las conversaciones/hilos de los emails de trabajo.
Eso queda reflejado en el ticket de redmine de forma que tienes que hacer scroll infinito para llegar al punto donde se añade la información en el cuerpo de cada email.
Pues bien, este script elimina de todo el ticket toda esa morralla que solo perjudica la lectura. Después de ejecutarlo, ¡qué a gusto y claro se puede leer ahora!
Además también elimina de las firmas todos esos enlaces absurdos de las redes sociales. Twitter, Linkedin, Facebook, Instagram de la empresa, pero vamos a ver ... ¿para qué son necesarios en hilos de incidencias entre compañeros de trabajo? ..
cierra.sh hace varias cosas al ticket que sele pase como parámetro:
- le pone fecha fin la del dia
- %realizado a 100%
- le añade un mínimo de tiempo "0.1"
- le cambia el Estado a Resuelta
- lo pone como cerrado
Y en eso gasté mi sábado (entre otras cosas).
DHCP detectar nuevos equipos en la red con BASH
El script empezó siendo mucho más simple y solo en bash, pero al final quería que me mandase un email cada vez que encontrase un nuevo equipo, y tuve que utilizar un programa hecho por mi en Go para mandar los emails.
Además utiliza primordialmente awk que es bastante rápido en procesar ficheros de texto.
Ya lo tenía hace muchos años hecho y funcionando perfectamente en la red de mi trabajo; estaba hecho en python para redes windows. detectar-y-avisar-nuevas-concesiones-de-ip-en-nuestra-red-dhcp.html
El script busca nuevos equipos por MACs y es sabido que ya hay formas de crear nuevas macs para cada conexión así que puede haber nuevos falsos positivos por ser el mismo equipo.
Para adaptarse a uno mismo se tendría que cambiar:
- los interfaces a poner en arp-scan
- la red a buscar
- todo lo referente al envío del email
Finalmente se pone este script en el crontab para que se ejecute cada cierto tiempo y ya está.
Una vez que recibo un aviso, busco el equipo, edito el fichero dhcp.txt poniendo el nombre que quiera en la última columna y ordeno por mac (esto último porque sí).
El fichero dhcp.txt tiene esta pinta:

Solo por poner ideas.
```
#!/usr/bin/env bash
# Función: enviar email cada vez que se detecte una mac distinta conectada a la red
# Fecha creación: 29.12.2021
# Autor: Julio
# Versión: 1.0
# Detalle:
# - se necesita instalar arp-scan
# - se necesita mandaemail hecho por mi en Go
# - contiene passwd
#
now=$(date +%d/%m/%Y"_"%T)
sudo arp-scan -x -I wlp59s0 192.168.0.0/24 > wdhcp_now.txt
sudo arp-scan -x -I enp58s0f1 192.168.0.0/24 >> wdhcp_now.txt
cat wdhcp_now.txt | sort -k2,2 | uniq > dhcp_now.txt
awk -F"\t" -v now="$now" '
NR == FNR {
mac[$2]=$0;
next;
}
{
if (mac[$2] == "") {
nuevo+=1
printf("\n%s\tdispositivo nuevo: %s", nuevo, $0)
#gsub("\\:",":",rit2)
print $0"\t"now"\t?" >> "dhcp.txt"
}
}
END {
if (nuevo>0) {
printf("\nse encontraron %s nuevos\n", nuevo)
print "semaforo" > "dhcp_nuevos.txt"
}
else {
print("\ntodo ok")
}
}
' dhcp.txt dhcp_now.txt
if test -f "/tu_ruta/dhcp_nuevos.txt"
then
cadena="email_emisor|tupassword|tuservidor_smtp|tu_puerto_smtp|destinatario|Nuevos_equipos_detectados_"$now"|.|dhcp.txt|"
echo -e "\nmando email"
mandaemail "$cadena"
rm dhcp_nuevos.txt
fi
rm wdhcp_now.txt
rm dhcp_now.txt
```
Exportar datos de Google Books e importar a GoodReads
Google Books parece abocado a desaparecer cualquier dia de estos tal como Google nos tiene acostumbrados. GoodReads está bien pensado y esperemos dure algo más.
Se trata de pasar nuestros datos de Google Books y pasarlos a GoodReads de la forma más fácil posible.
- exportar a xml de GoogleBooks
- pasar script de lua
- con los datos de salida de ese script grabar fichero .csv (recomienda GoodReads separador la ",")
- importar a GoodReads
Exportar
GoogleBooks permite exportar los datos que tengamos de libros exportando de librería en librería (prime problema como tengamos varias "Estanterías") en formato XML. Tenemos que ir a la estantería que queramos y en el botón de configuración escoger la opción de exportar a xml.
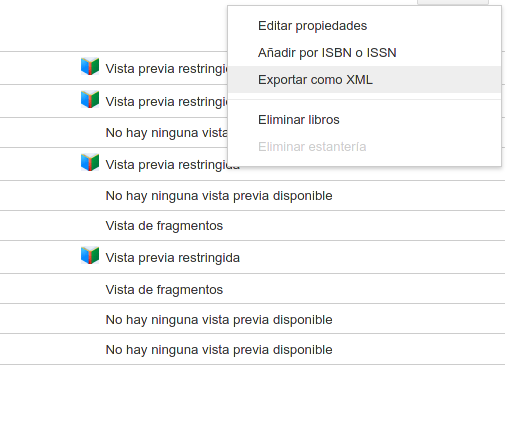
Obtendremos ficheros xml de esta pinta
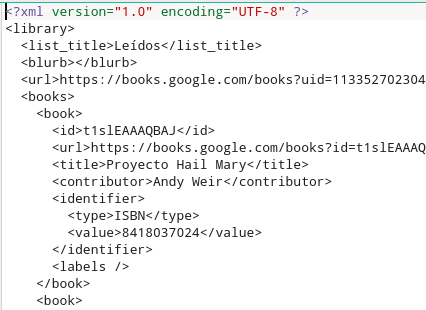
Script en Lua
Pasar el siguiente script de forma './xml_googlebooks.lua ficheroxmlexportado'
#!/usr/bin/env lua
--[[ 29.07.2021
* exporto estantería a estantería de google books
* prefiero pasar: './xml_books.lua tintin.xml>> tsv_biblioteca.csv' uno a uno
* ese fichero tsv pasarlo a formato columnas goodreads que parece más normal
--]]
local xml2lua = require("xml2lua")
local handler = require("xmlhandler.tree")
function resumenxml(fichero)
--print(fichero)
local i, p
local libreria, titulo, autor, idtipo, idvalor
local xml = xml2lua.loadFile(fichero)
local parser = xml2lua.parser(handler)
parser:parse(xml)
libreria = handler.root.library.list_title
print("FICHERO\tLIBRERÍA\tTÍTULO\tAUTOR\tidTIPO\tISBN")
for i, p in pairs(handler.root.library.books.book) do
titulo = p.title
autor = p.contributor
idtipo = ''
idvalor = ''
if (p.identifier ~= nil) then
idtipo = p.identifier.type
idvalor = p.identifier.value
end
print(string.format("%s\t%s\t%s\t%s\t%s\t%s", fichero, libreria, titulo, autor, idtipo, idvalor))
end
end
resumenxml(arg[1])
Obtendremos una salida del tipo

que podremos redireccionar a fichero o lo que queramos. Las cabeceras que he puesto en el script no coinciden con las que GoodReads quiere pero prefiero así para tener más claro lo que meter en cada columna del siguiente paso.
Genera tu fichero para importar como tú quieras
Por último se recomienda generar un '*.csv' con la cabecera de columnas que recomienda GoodReads pero con los datos obtenidos anteriormente.
Title, Author, ISBN, My Rating, Average Rating, Publisher, Binding, Year Published, Original Publication Year, Date Read, Date Added, Bookshelves, My Review
Ya podemos ir a GoodReads a importar el fichero.
https://www.goodreads.com/review/import
Ahorrando tiempo de excel con bash awk
Tarea repetitiva con excel
Debido a un proceso de unificación de bases de datos, me pedían varias veces un excel resultante de la combinación de varios excel.
Si veo que esto será un proceso habitual y necesario a lo largo del tiempo, no me complico y prefiero hacer un programa que me lo genere directamente, pero como no es el caso pues será para unas pocas veces prefiero combinar los datos que ya tengo a un fichero.
Los ficheros excel de los que partía tienen varias columnas, más de 80, y el usuario que pedía el informe quería sólo unas columnas y en un orden específico. Ambas excel contenían en total varios miles de registros (>100K) por lo que siempre tocaba hacer:
- abrir los dos excel
- eliminar las columnas innecesarias
- insertar columnas nuevas para por ejemplo sumas de otras (ventas, stock ..)
- utilizar el BUSCARV para enlazar datos de una excel con la otra
- reordenar las columnas con lo orden que se nos pide (cortar/insertar columna).
Bien, al final con la práctica y dependiendo de la memoria del pc que se utilice, todo eso lleva unos minutos.
Pero el Excel/Libreoffice cada vez que mueve columnas con fórmulas, si se tiene el cálculo automático activado, sufre de pausas de tiempo que molestan mucho. Lo mismo como hayas añadido tablas dinámicas.
Y menos mal que esta vez NO hacemos filtros de datos ni tampoco ordenamos, porque eso multiplica el tiempo de pausas en cada operación de cortar-insertar-filtrar-ordenar del Excel.
Ahorrando tiempo con awk
Me fastidia hacer siempre lo mismo pudiendo emplear el tiempo para otras cosas, además de que en las tareas repetitivas manuales es más fácil equivocarse y que te toque deshacer para volver a empezar.
Así que decido hacer un script en bash utilizando awk que me lea los dos ficheros csv y me genere un resultante con todo lo pedido. ¡no tarda más de 2 segundos de reloj! también dependiendo de la máquina.
Este es el script. Los ficheros csv iniciales son bv.csv y bz.csv de unos 21Mb cada uno.
#!/usr/bin/env bash
#cp /media/julio/vbbdd/datos_valladolid/ARTICULOS_Valladolid.csv bv.csv
#cp /media/julio/vbbdd/datos_zamora/ARTICULOS_Zamora.csv bz.csv
#
awk -F';' '
NR==FNR {
zstock[$1]=$8;
zventas[$1]=$85;
zmcam[$1]=$86;
next;
}
{
gsub("\r","");
vventas=$85;
vstock=$8;
vmcam=$86;
cventas=vventas+zventas[$1];
cstock=vstock+zstock[$1];
cmcam=vmcam+zmcam[$1];
cggc=" ";
encargo=" ";
if ($1 == "CODIGO") {
cventas="COOP_VENTAS_2019";
cstock="COOP_STOCK";
cmcam="COOP_UNIDADES_PDTES_PROVEEDOR";
cggc="CODGGC";
encargo="ENCARGO";
}
print $1,cggc,$6,$2,$40,$38,$39,$22,$20,$21,$30,$26,$41,$54,$55,$56,$57,$35,$3,cstock,cventas,cmcam,$5,encargo,$4
} ' OFS='\t' bz.csv bv.csv > bbdd_arts.csv

Dije 2 segundos y no llega ni a uno.
Lee primero un fichero separado por ";" donde recogemos los datos que necesitaremos consolidar, luego con el segundo fichero que lee va componiendo las columnas con las sumas, se crea la cabecera de texto con las columnas nuevas, y por fin guardamos todo un fichero separado por tabuladores listo para leer por el destinatario en su Excel.
Hay que tener en cuenta, repito, que no ordenamos ni tampoco hacemos filtros de datos. Si fuera así, el trabajo en Excel sería todavía más tedioso y en cambio con bash serían un par de palabras más añadidas al script.
Ver la cabecera y número de columna de un fichero csv
El inconveniente que se podría decir es que es laborioso con awk saber el número de campo que queremos imprimir, pues nos toca contar el orden de los campos para saber por ejemplo que la columna "ALTO" corresponde con el número de campo $54 del csv.
Para ello se tiene otra función que se carga automáticamente en bash que es fieldsc y muestra los campos de un csv y su numeración de forma fácil, y tampoco es una función muy complicada:
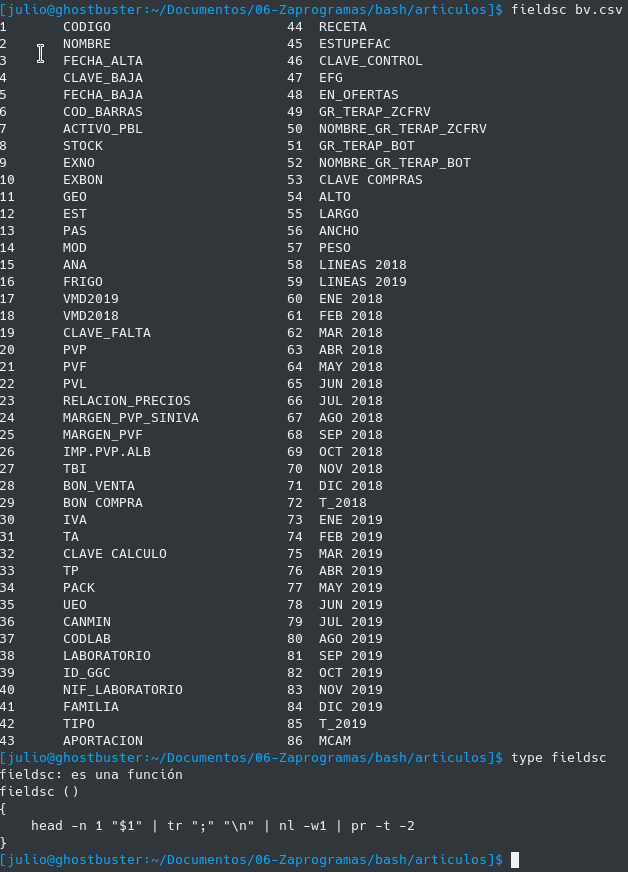
Como decía esta función y muchas otras las tengo disponibles siempre en el terminal pues se carga en el .bashrc con source bash_functions.sh.
Por cierto esta función es gentileza de Robert Mesibov ( BASHing data ) un maestro en lo que él mismo se autodenomina "data auditor and cleaning". Mucho que aprender de él en estos tiempos del Big Data.
Crear ficheros csv a partir de uno exportado con ^%GOGEN en MUMPS
sobre exportar globals con ^%GOGEN
La utilidad ^%GOGEN nos permite sacar a disco dentro de la red donde se encuentre el servidor de Caché GLOBALS o ficheros de la base de datos. Permite sacar uno o varios a la vez.
El formato que tiene si lo editamos es parecido a esto:
Disfrutando de la linea de Comandos II, resultados de un Web Service a fichero excel
Continuación de Disfrutando de la linea de comandos I
Ya tenemos el resultado del web service obtenido con Curl
Y ahora tenemos que desgranar el resultado devuelto en JSON en ficheros excel. Habrá librerías o utilidades que dado un fichero texto csv lo convierta a formato Excel, pero si queremos ahorrarnos ese paso podemos crear ficheros tsv (separador tabulador) y nombrar a los ficheros con la extensión ".xls". Con ello se consigue que la mayoría de los ordenadores consigan abrir ese fichero en la hoja de cálculo.
Como ya comenté el formato JSON es repetitivo en mi opinión y más complicado de ser tratado por máquinas que un simple csv. Utilizaremos la herramienta jq que es capaz de desgranar cada elemento del JSON y además con una simple opción la formatea a formato @tsv o @csv.
Gnuplot y bash, registro de carreras
Los que corremos, distancias superiores al kilómetro, solemos medir la velocidad no en Km/h ni en m/s sino que lo hacemos en relación al ritmo, en minuto/Km. Solemos decir voy a 4:30 o 5:55.
Tengo apuntados los entrenos desde hace mucho tiempo, con lo cual registro distancia, tiempo y título de descripción corta del trayecto efectuado entre otras muchas cosas.
En R ya tengo un programa que me saca muchos muchos datos, pero ahora me apetecía seguir aprendiendo bash y por ello decidí cómo sacar algunos datos e incluso un gráfico sólo con herramientas disponibles en la línea de comandos.
Disfrutando de la linea de Comandos I Web Services con Curl
Intento no extenderme en cada uno de los puntos.
Linux, potencia en la línea de comandos
Tengo varios programas realizados en python y en Go que recogen datos utilizando web services, los manipulan, y los registran en mi ERP. Luego se utilizan otros servicios también con otros programas para devolver datos actualizados.
Cada vez más me gusta el poder utilizar herramientas que me da el propio sistemas operativo, sin necesidad de realizar programas en python o Go.
Es increíble la potencia de "awk", "sed", "grep" para manipular datos. Es también complicado pero con una línea en "bash" se puede hacer lo que en lenguajes de programación pueden ser 10.
FreeBSD como repositorio de copias
En mi trabajo la red se compone principalmente de servidores windows, aunque los hay Ubuntu, Suse y algunas versiones de FreeBSD. Los puestos de clientes más de lo mismo.
En estos dias el ransomware está al orden del día, por lo que aparte de las medidas de seguridad diarias como copias, antivirus, firewall, avisos al personal sobre el uso de internet y los correos, etc ... es mejor tener un plan para cuando te toque el día restablecer cuanto antes los servidores y los datos.
En una red windows es bastante habitual tener carpetas compartidas, para grupos de empleados, intranet, documentación, etc.. El ransomware las utiliza para expandirse por lo que me tocó hacer una revisión completa de las que eran verdaderamente necesarias y sobre todo ajustando los permisos a los mínimos necesarios. Lo mismo con los usuarios, bajando privilegios de acceso lo más posible.
Control Cámara IP con ~~Whatsapp~~ Telegram

Se trata de utilizar la cámara IP con Wifi Foscam FI9804W que permite uso en exteriores.
Con la aplicación de mensajería Telegram, podemos activar la detección de movimiento que lleva esa cámara, desactivarla, pedir una foto, etc..
Así no nos hace falta ni estar delante de ella, ni ningún acceso web al interface de la cámara.
Un pequeño video para mostrar lo que se pretende.
video resumen
Where do you store your passwords
Do you trust in cloud services like Dropbox, Onedrive, Google Drive ... to store your private data?
No I don't. I prefer local data. If my data is stolen is only my fault.
Do you need many passwords to manage your workday?
Yes I do.
Do you prefer plain text files over other kind?
Yes I do. They will be read forever? I guess...
Do you want a little security for your data?
Encrypts your data!
Telegram Wifi On or Wifi Off
Sending a Telegram message I can enable or disable Wifi in my home router.
Hey Kids! go to study and leave off mobile phone!
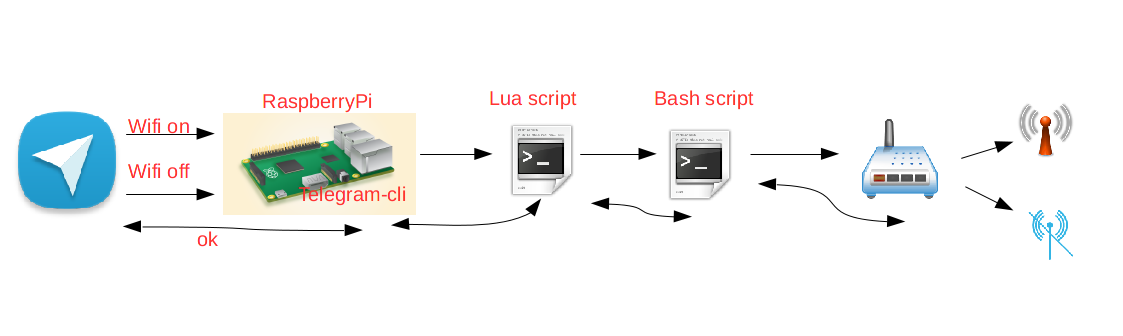
Telnet script to disable wifi in router Observa Telecom
My son sometimes is connected to internet until several hours past night.
I tried to convince that he needs several hours of sleep... but he is 14 years old...
So the fastest way is disabling wifi at home, and I made it in the easiest way too.
observawifidisable.sh
```
sh << EOF | telnet 192.168.1.1
sleep 1
echo 1234
sleep 1
echo password
echo wlan disable
sleep 2
echo exit
sleep 1
echo Y
EOF
```
I put this scritp in the crontab of my home server
10 0 * * * sh /home/me/observa_wifi_disable.sh > /home/me/observa_wifi_disable.sh
Then I made another script, same disable but now enabling wifi. Only I had to change wlan disable by wlan enable
Yes, I know. It's ugly code, but It works with little lines.
Disfar-R-Telegram
A veces es mejor recibir una imágen que muchas lineas de texto con porcentajes...
Y sin intervención de usuario mejor ;-)
todos los dias de forma automática